
2019年1月中旬から多発するようになりました。他にも同じ現象に遭遇している人が居ると思い、解決案を提示します。
解決案

- 現象が発生する
- サーバを停止する
- インスタンスタイプを上位のものに変更する
- サーバを起動する
- 現象が発生しないことを確認する
- サーバを停止する
- インスタンスタイプを元に戻して、サーバを起動する
- 現象が発生しないことを確認する
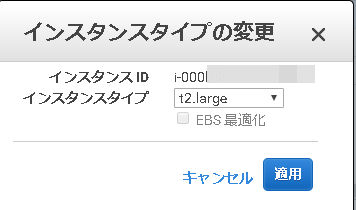
自分の場合はt2.microインスタンスを使っていてスローダウンに見舞われました。他のインスタンスでも同じやり方でクリアできると思います。
それか、そもそも現象自体が発生しないか。

発生している現象
スローダウンとはサーバの反応が極めて悪くなること。
一般的に考えられる要因は
- アクセスが極端に集中している
- 誰からイタズラ(攻撃、ハッキングとも言う)されている
- ハードウェアが壊れそう
一回こうなるとサーバは症状が回復しない限り使えません。

トラブル詳細
今回のトラブル
おかしな点は、スローダウンしているのはサーバ上で動いているWordPressのみで、サーバそのものは健康ということ。sshでログインしても普通に操作できます。
ただ、Wordpressが突然動作しなくなる、ということです。20時以降に発生する事が多いですが、日中に発生することもあります。
一度問題が発生すると、特に対処しないかぎり解消されるのをひたすら待つことになります。翌朝自然に解消していることもあれば24時間使えない事もあります。

試しても症状が改善しなかったこと
- サーバ再起動
- WordPressテーマの変更
- WordPressプラグインの全無効化

エラー調査

私がAWSに携わり2年ですが、今までスローダウントラブルに遭遇したことは一度もありません。サーバも自分しか使っていないので、アクセスが集中したり誰かに狙われる事もないはず。

そうすると原因として考えられるのは
- 自分の家からAWSサーバ(Amazon)に辿り着くネットワーク帯域がBusy
- AWSサーバが原因
どちらかです。もし「1.」だったらお手上げです。中国のネットワークは自分ではどうしようもできません。あと、もし「1.」だったら、もっと早くから現象が発生しているはず。
ということで「2.」でぼぼ決定です。

エラーログ
そしてサーバのエラーログを調査します。
■見るファイル
/opt/bitnami/apache2/logs/error_log

■エラー内容
[Fri Jan 11 13:33:26.917516 2019] [pagespeed:error] [pid 1770:tid 140159034926848] [mod_pagespeed 1.9.32.14-0 @1770] Slow read operation on file /opt/bitnami/apache2/var/cache/mod_pagespeed/!clean!time!: 65.402ms; configure SlowFileLatencyUs to change threshold\n
[Fri Jan 11 14:41:12.737575 2019] [proxy_fcgi:error] [pid 1770:tid 140158925821696] (70007)The timeout specified has expired: [client 133.242.54.xxx:57014] AH01075: Error dispatching request to : (polling), referer: https://xxx.com/wp-admin/plugins.php
ありますね。1ファイル読み込むのに65秒かかっています。
注意点
ということで、スローダウン現象が発生した人は(自己責任で)先の手順を試してみて下ください。
mySQLの設定ファイルが勝手に書き換えられる、かも?
詳しくは分かりませんが、AWSではインスタンスタイプを変更すると、mySQLの設定ファイルなどが(/opt/bitnami/mysql/bitnami/my.cnf)が構文精査されるようです。
この時、設定ファイルに誤った記述がある場合、それが自動で削除されるのでご注意を。

これが普通誤りなら問題はありませんが、その設定は意味のある値で記述した時は問題なくて、たまたまこれまで動いていたというケースだと、本問題の処置後にその機能が動かなくなります。
自分の場合は以下の設定がNGでした。
| [mysqld] #wait_timeout = 120 long_query_time = 1 query_cache_limit=2M query_cache_type=1 query_cache_size=256M innodb_buffer_pool_size=2048M #innodb_log_file_size=128M #tmp_table_size=64M #max_connections = 2500 #max_user_connections = 2500 #innodb_flush_method=O_DIRECT #key_buffer_size=64M[mysqld] event_scheduler=ON |
赤い部分がNG。おそらく、mysqldと2回書いたからNGなのかな。この部分はインスタンスタイプ変更後に無くなります。
やる前に念のためmy.cnfのバックアップを取っておきましょう。
AWSも万能ではない
今回実感しました。
目の前で問題が起きているのにどうしようもないのはかなり辛いです。

サポートへの技術的な問い合わせは別料金です。即時対応が必要な場合は厳しいところです。


コメント